|
Jade Choghari I'm a Robotics Engineer on the LeRobot team at Hugging Face 🤗, where I work on large-scale robot learning, simulation, and transformer-based policies. Before robotics, I contributed to computer vision and multimodal AI across text, images, audio, and video. I am also a Computer Science student at the University of Waterloo. |

|
ResearchI'm interested in robot learning, large-scale simulation, and vision-language-action (VLA) policies. My research focuses on building scalable environments, datasets, and transformer-based control systems that enable robots to perform complex manipulation and real-world tasks. Below is a selection of my research and open-source work. |
Selected Projects
|
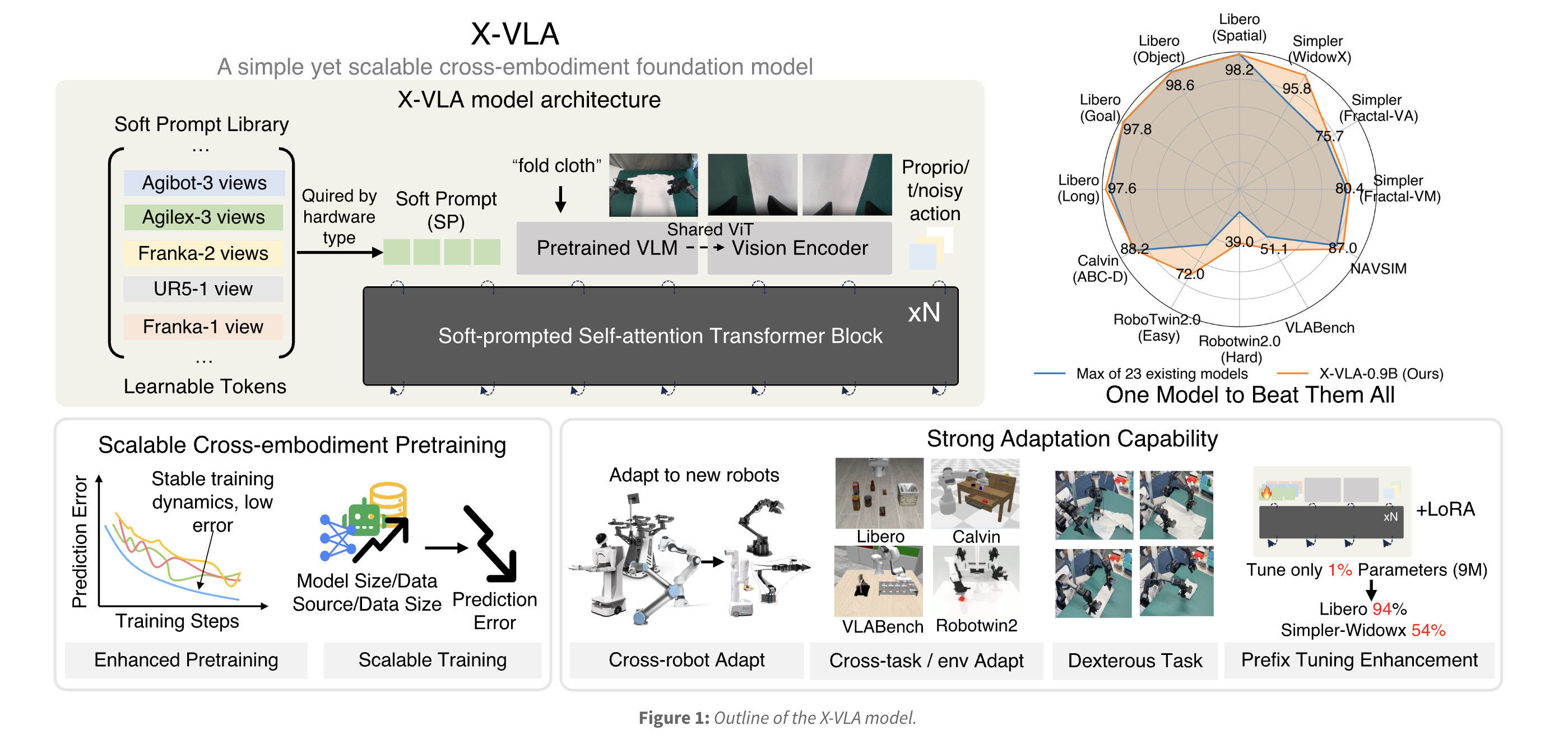
X-VLA: Soft-Prompted Vision-Language-Action Foundation Model
2025 Built X-VLA in LeRobot, the first soft-prompted VLA model capable of scaling across many embodiments, cameras, action spaces, and environments through a unified transformer backbone. We release 6 checkpoints, including a cloth-folding model achieving 100% success over a 2-hour continuous run, with a 1.5k-episode cloth-folding dataset to support community fine-tuning. Docs/Blog, PR, Twitter |
|
EnvHub: A Community Push to Scale Simulation Environments
2025 Launched EnvHub, a large-scale initiative to make simulation environments shareable and reusable across the community. Enables one-line loading of Isaac, MuJoCo, Genesis, and custom tasks into LeRobot—reviving the 2017 OpenAI Gym call-to-action, but for modern robot learning. Docs, Twitter |
|
LeRobot: Unified Evaluation Stack for VLA Benchmarks
2025 Built the evaluation stack for LeRobot, integrating LIBERO, MetaWorld, and other benchmarks to evaluate VLA models across 130+ manipulation tasks. Github, Twitter |

|
VLAb: Pretraining Toolkit for VLA Models
2025 A streamlined library for pretraining VLA models with multi-dataset support and distributed training. Built the pretraining stack used to reproduce SmolVLA and scale workflows across multi-GPU and SLURM clusters. Github |

|
LeRobot: Machine Learning Framework for Real-World Robotics
2025 An open-source PyTorch library for end-to-end robot learning, providing datasets, policies, simulation tools, and training pipelines across diverse robots. Github |

|
Gym-Genesis: GPU-Accelerated Simulation Environments for Robotics
2025 A vectorized Gym-style environment wrapper for the Genesis physics engine, enabling thousands of parallel environments on GPU for high-throughput robot learning. I developed core environment wrappers, improved observation pipelines, and added SO101 with imitation-learning demos. Github |
|
Roomi Robot: Open-Source Autonomous Housekeeping Robot
2025 A low-cost mobile manipulation robot for housekeeping tasks, combining a mobile base, dual arms, and multi-camera perception for tasks like towel replacement, trash collection, and restocking. Github |
|
|
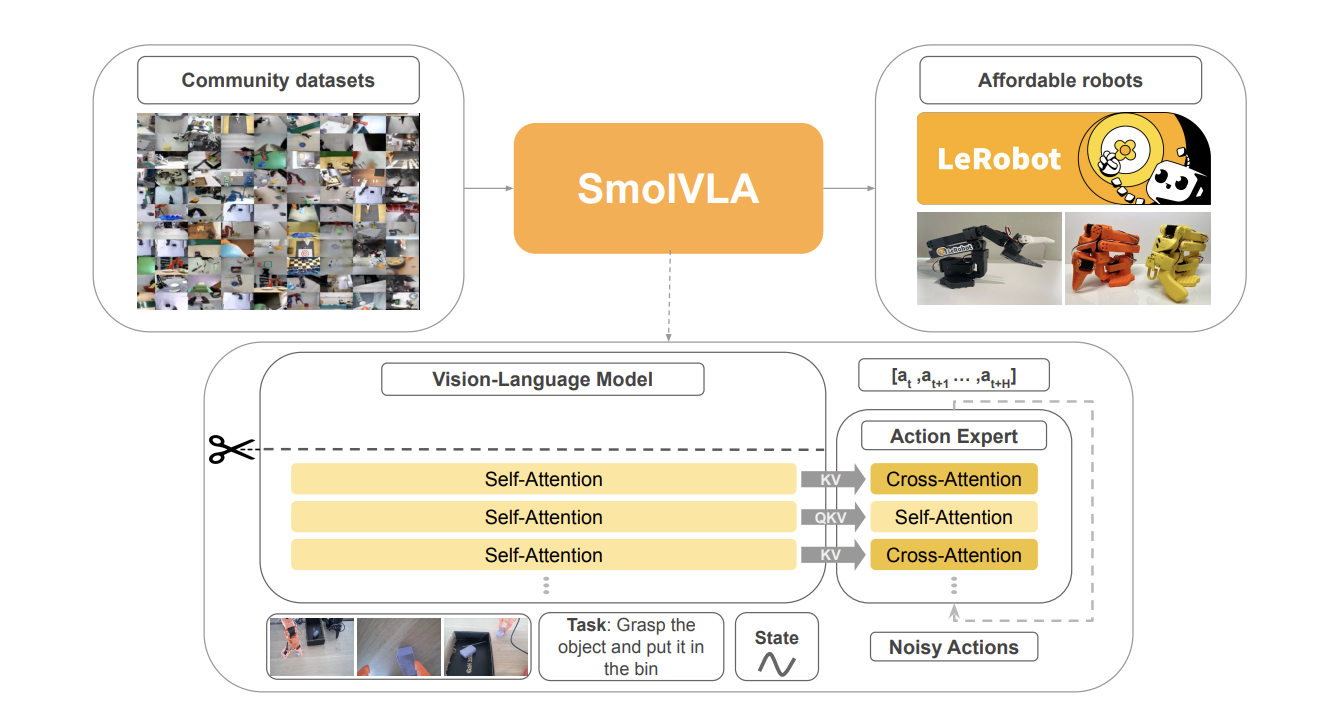
SmolVLA: A Vision-Language-Action Model for Efficient Robotics
2025 A lightweight VLA model designed for affordable robot learning with scalable simulation and training pipelines. I built the simulation stack, developed scalable environments, and improved throughput, realism, and reproducibility for large-scale VLA training. Github |
|
RT-DETRv2: Improved Real-Time Detection Transformer
2025 An enhanced real-time DETR with selective multi-scale sampling, optional discrete attention for easier deployment, and dynamic data augmentation for stronger performance. I contributed the official RT-DETRv2 integration in Hugging Face Transformers, including model architecture, preprocessing, and training utilities. Hugging Face Transformers, LinkedIn |
|
|
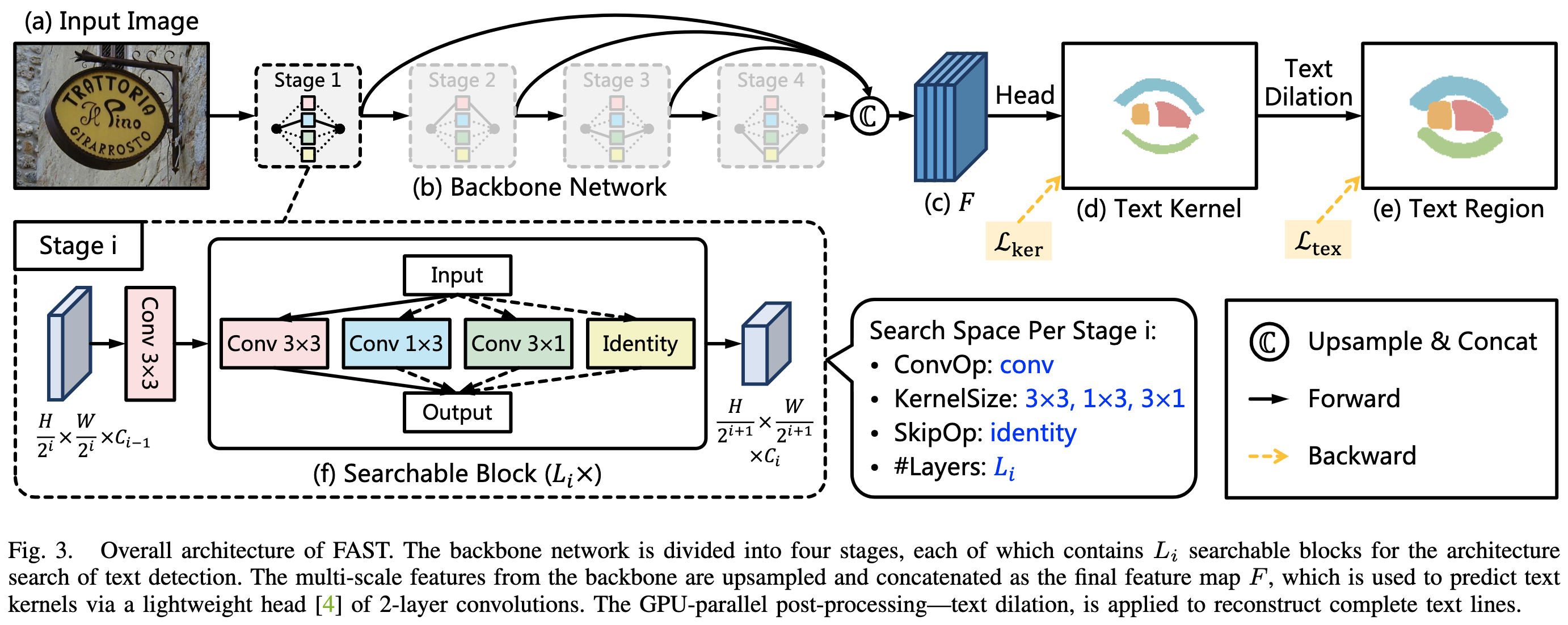
TextNet: Fast Backbone for Arbitrary-Shaped Text Detection
2023 A NAS-designed backbone for detecting arbitrarily-shaped and rotated text, using asymmetric kernels to capture extreme aspect ratios. I contributed the TextNet integration in Hugging Face Transformers and added the TextNetForImageClassification variant. Hugging Face Transformers, Twitter |

|
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
arXiv 2024 A multimodal LLM specialized for mobile UI screens, with strong referring, grounding, and reasoning abilities across fine-grained UI tasks. I integrated Ferret-UI into Hugging Face and contributed to the model and demo tooling. Hugging Face Transformers Twitter |
|
VidToMe: Video Token Merging for Zero-Shot Video Editing
arXiv 2024 Improves zero-shot video editing by merging redundant tokens across frames to enhance temporal consistency and reduce memory usage. I integrated VidToMe into Hugging Face and helped build the public demo. Github, Twitter |
|
|
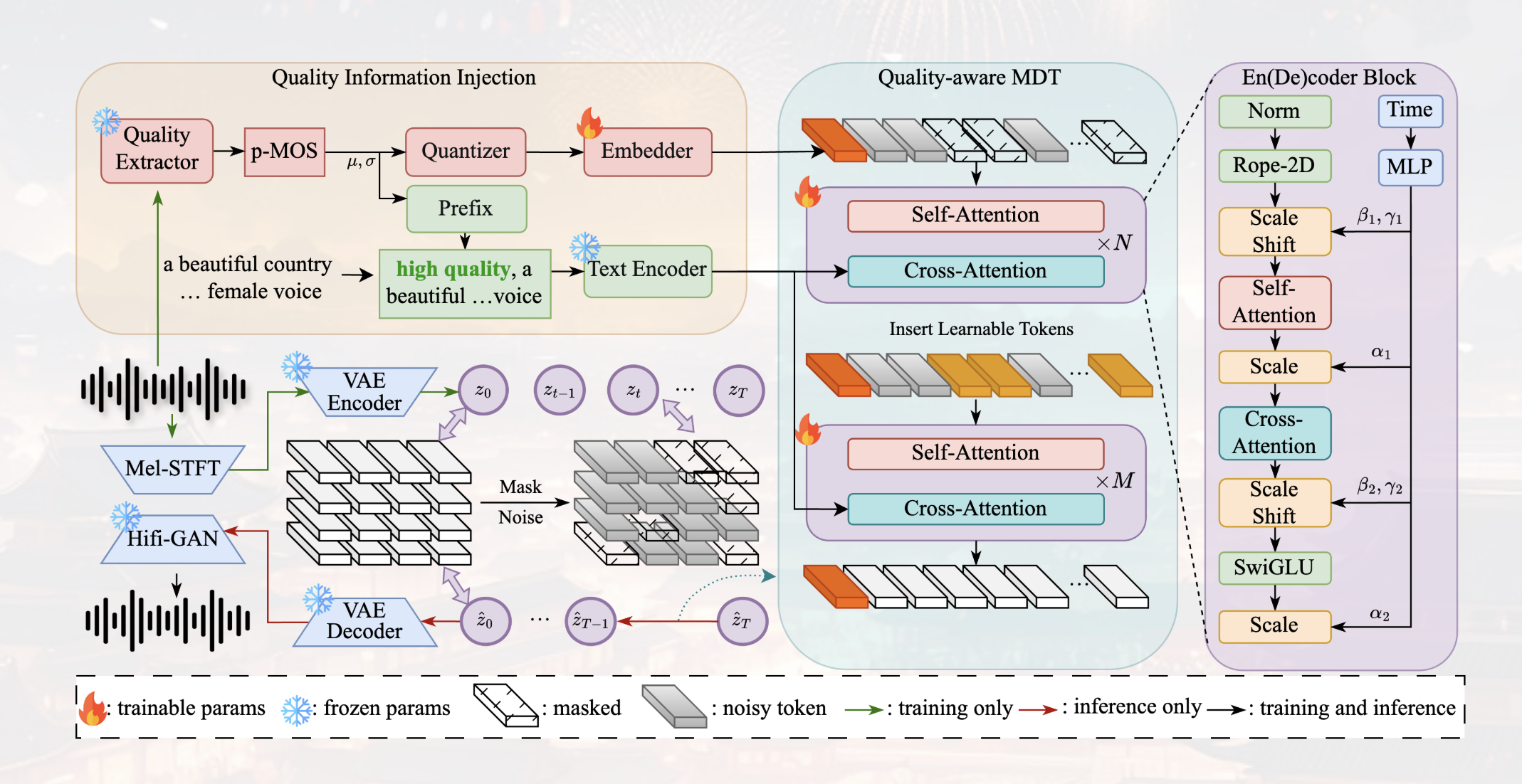
Quality-Aware Masked Diffusion Transformer for Music Generation
arXiv 2024 Introduces a quality-aware training framework and masked diffusion transformer for high-fidelity text-to-music generation, achieving SOTA results on MusicCaps and Song-Describer. I integrated QA-MDT into Hugging Face and contributed to model and demo tooling. Github, Twitter |
|
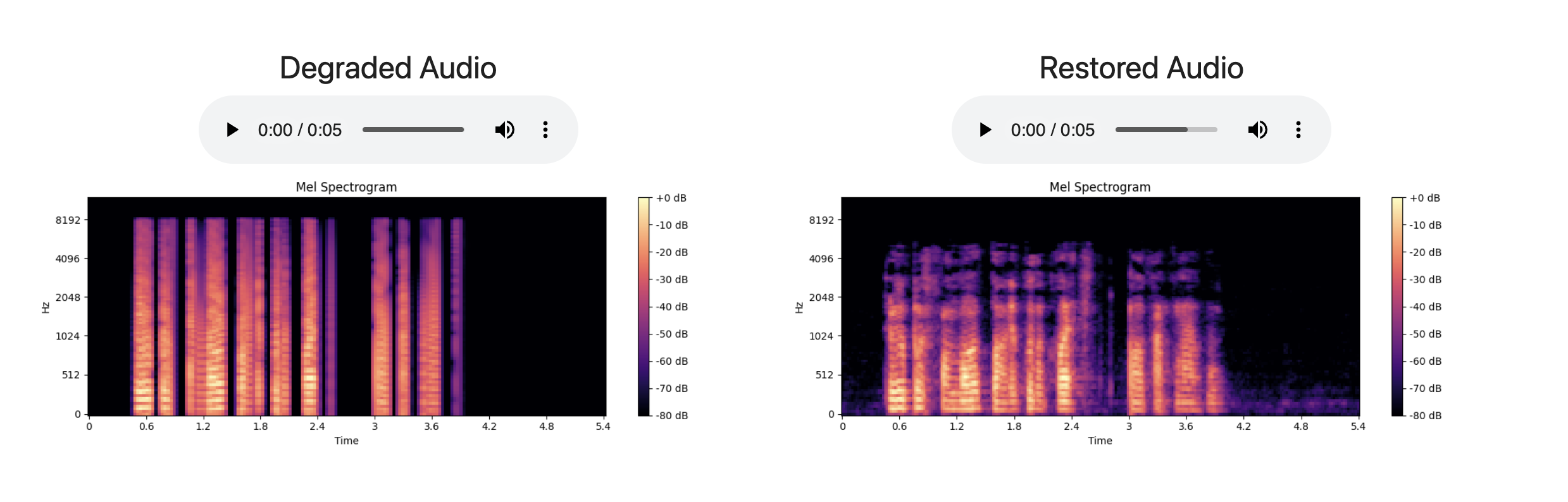
VoiceRestore: Flow-Matching Transformers for Speech Recording Quality Restoration
2024 Restores degraded speech using a unified flow-matching transformer trained on synthetic data, handling noise, reverberation, compression, and bandwidth artifacts. I integrated VoiceRestore into Hugging Face and contributed to the demo + tooling. Github, Twitter |
|
VFusion3D: Scalable 3D Generation from Video Diffusion Models
ECCV 2024 Learns 3D assets from a single image using video diffusion models and synthetic multi-view data. I integrated VFusion3D into Hugging Face, built the full model architecture, and created the public Gradio demo. Github |
|
|
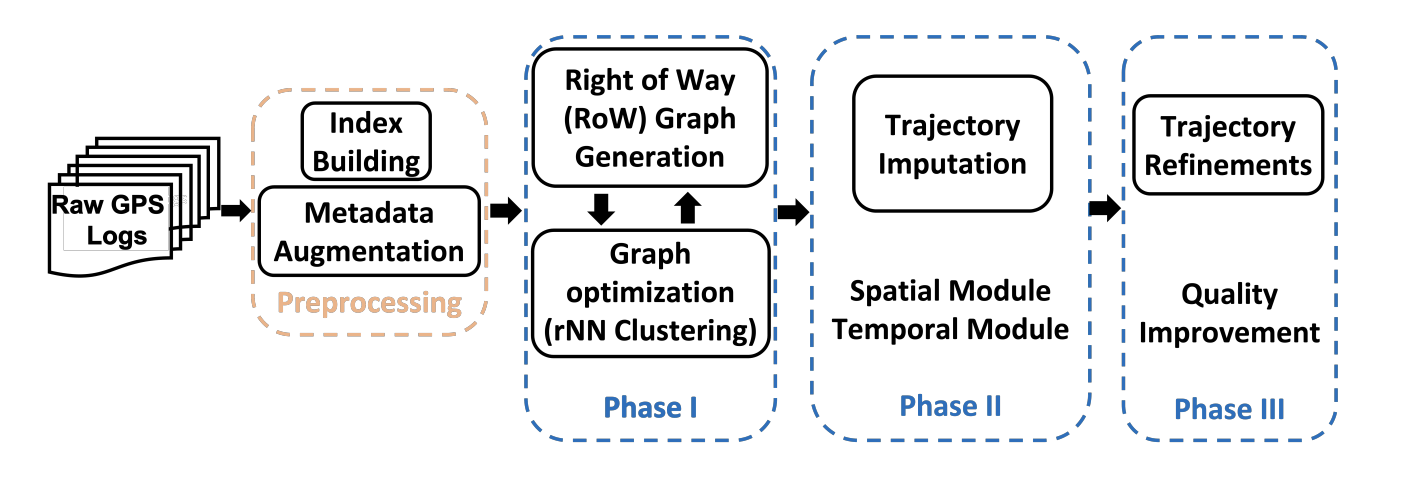
GTI: A Scalable Graph-Based Trajectory Imputation Method
ACM SIGSPATIAL 2023 GTI is a scalable trajectory imputation approach that reconstructs sparse GPS trajectories without relying on existing maps, enabling data completion for map construction and urban mobility applications. Paper |